現在使用しているデスクトップPC(7年選手)のSSDの容量が120GBと少なく、容量がほぼ限界まできていたので、SSDを比較的大容量のものに入れ替えることにしました。
これまで、グラフィックボードや電源の交換の経験はありますが、ストレージの入れ替えはノートパソコンのHDDぶりです。
ド素人なりに、忘備録を残しておきます。
新しいSSD
元のSSD
データ移行のため、SSD接続用にAUKEYの2.5インチSSD ケースを使いました。
SSDのクローン作業はすぐ終わると思っていましたが、予想外に手間取り結局何度か試すことになりました。
元よりも容量が大きいSSDへの移行だったため、パーティションサイズを変更してクローンしたかったのですが、うまく扱えませんでした。最終的に、おすすめ記事が多いEaseUS Todo Backup Freeではなく、AOMEI Backupper Standardを使いました。
クローン後は、元のSSDが繋がっていたSATAに差し替えて換装完了です。
問題なくWindowsも起動しました。
換装前後のCrystalDiskMarkのベンチマークスコアは以下の通りです。
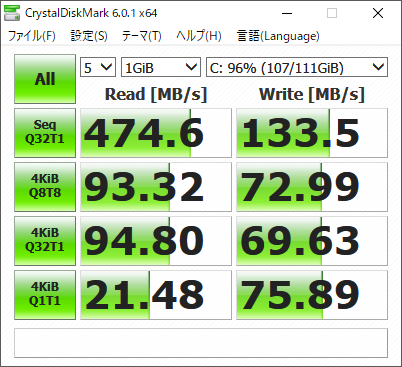 |
 |
A-DATA S511(120GB)
|
Crucial MX500(500GB)
|
容量にかなり余裕ができ、書き込み速度も向上し、大変満足のいく結果となりました。




